はじめに
悲しみや喜びの表情をモーフィングするには,まず顔のランドマークを検出する必要がある。やり方は様々で回帰分析ツリー,物体検出,回帰学習など,様々な方法があるが,Pythonでランドマークをやる場合,dlibライブラリを用いることでリアルタイムで高精度なランドマーク検出できるようだ。今回はこれのメモをのこす。

必要なライブラリ
pip install dlib
pip install imutils
pip install opencv
pip install libopencv
pip install py-opencv
*どうやらdlibライブラリは,一筋縄ではいかないようだ。方法は下記の通り。
①AIのDL(サイト):「shape_predictor_68_face_landmarks.dat.bz2」
②cmakeソフトのインストール:参照サイト1,サイト2
③環境変数:「詳細設定タブ→ユーザ環境変数→システム環境変数→環境変数」で,変更後pythonの会話画面でcmakeパスが通っているか確認する。
where cmake
where cmake-gui
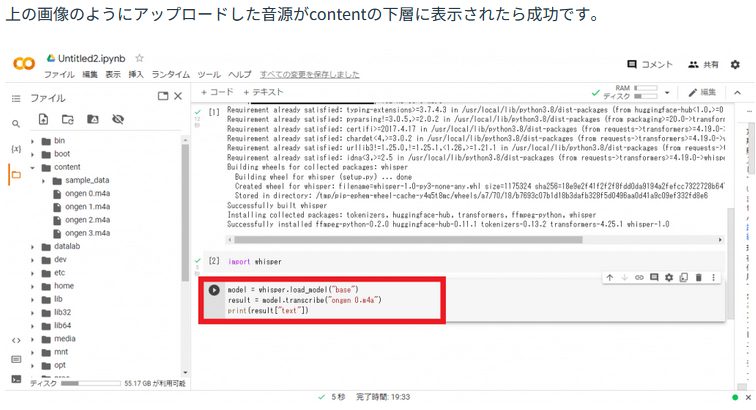
ランドマーク&モーフィングの実行
喜びの場合,参考基となる0%,100%の画像が必要となる。これらの画像と上記のライブラリ,ソフトをc直下のファイル内に入れたうえで下記プログラムを実行する。プロンプトは下記のようにした(作りかけ…)。一先ず,耳と髪をそぎ落とす。
①真顔(画像0:0%)から恐怖の顔(画像8:100%)へ変化するモーフィング画像を7段階で作成する。具体的なモーフィングレベルは画像0=0%、画像1=12.5%、画像2=25.0%、画像3=37.5%、画像4=50.0%、画像5=62.5%、画像6=75.0%、画像7=87.5%、画像8=100%。画像0と画像8は添付してある写真を用いる。
②顔の部分が見えるように楕円形に加工する。その際、髪の毛と耳は入らないように切りとる。
import cv2
import dlib
import numpy as np
import imutils
from imutils import face_utils
# 顔のランドマーク検出器をロード
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
# Load the images
img0 = cv2.imread(r"C:\ukeno\m01_neu_0.jpg")
img8 = cv2.imread(r"C:\ukeno\m01_fea_0.jpg")
# 顔のランドマークを検出する関数
def get_landmarks(image):
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
rects = detector(gray, 1)
for rect in rects:
shape = predictor(gray, rect)
return face_utils.shape_to_np(shape)
return None
landmarks0 = get_landmarks(img0)
landmarks8 = get_landmarks(img8)
if landmarks0 is None or landmarks8 is None:
print("顔のランドマークが検出できませんでした。")
else:
# 画像をモーフィングする関数
def morph_images(img1, img2, landmarks1, landmarks2, alpha):
points = [(int((1 - alpha) * x + alpha * y), int((1 - alpha) * x1 + alpha * y1)) for (x, y), (x1, y1) in zip(landmarks1, landmarks2)]
img1 = np.float32(img1)
img2 = np.float32(img2)
result = np.zeros(img1.shape, dtype=img1.dtype)
# 中心部分のランドマークインデックスを取得
# 目、鼻、口の周りの領域
central_indices = np.concatenate([range(17, 27), range(29, 36), range(48, 68)])
mask = np.zeros(img1.shape[:2], dtype=np.uint8)
# 中心部のランドマークの凸包を求めてマスクを作成
cv2.fillConvexPoly(mask, np.array([points[i] for i in central_indices], dtype=np.int32), 255)
# モーフィング処理
for triangle in face_utils.FACIAL_LANDMARKS_IDXS.values():
pts = np.array([points[i] for i in triangle if i < len(landmarks1)], dtype=np.int32) # インデックス範囲内のみ使用
cv2.fillConvexPoly(result, pts, (255, 255, 255))
morphed = cv2.bitwise_and(img1, img1, mask=mask)
result = cv2.addWeighted(img1, (1 - alpha), img2, alpha, 0, result)
return result
for i, alpha in enumerate(np.linspace(0, 1, 10)): # 0から1まで10ステップ
morphed_image = morph_images(img0, img8, landmarks0, landmarks8, alpha)
filename = f"C:\\ukeno\\morphed_image_{i}.jpg"
cv2.imwrite(filename, morphed_image)
出力結果
0~9の順番で並べていないが、これはどっからどう見ても失敗だろうな。モーフィングが上がるにつれてボヤケている。おそらく、ランドマークのプログラムがよくないんだろう。そもそも、髪と耳がカットされてないみたいだ。
(著作権でのせられない)
ランドマーク
やはり,高橋啓治郎先生のつよつよAIの方が,ポイントが多く倍以上あった。これもGithubから入手可能なようで,これを基にできたらやった方がいいかも。


ランドマークのプログラム例(参照サイト)
# coding:utf-8
import dlib
from imutils import face_utils
import cv2
# --------------------------------
# 1.顔ランドマーク検出の前準備
# --------------------------------
# 顔検出ツールの呼び出し
face_detector = dlib.get_frontal_face_detector()
# 顔のランドマーク検出ツールの呼び出し
predictor_path = 'shape_predictor_68_face_landmarks.dat'
face_predictor = dlib.shape_predictor(predictor_path)
# 検出対象の画像の呼び込み
img = cv2.imread('Girl.bmp')
# 処理高速化のためグレースケール化(任意)
img_gry = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# --------------------------------
# 2.顔のランドマーク検出
# --------------------------------
# 顔検出
# ※2番めの引数はupsampleの回数。基本的に1回で十分。
faces = face_detector(img_gry, 1)
# 検出した全顔に対して処理
for face in faces:
# 顔のランドマーク検出
landmark = face_predictor(img_gry, face)
# 処理高速化のためランドマーク群をNumPy配列に変換(必須)
landmark = face_utils.shape_to_np(landmark)
# ランドマーク描画
for (i, (x, y)) in enumerate(landmark):
cv2.circle(img, (x, y), 1, (255, 0, 0), -1)
# --------------------------------
# 3.結果表示
# --------------------------------
cv2.imshow('sample', img)
cv2.waitKey(0)
cv2.destroyAllWindows()






{kind=link}