サンプル動画
開発環境準備
・Chat GPT:テキストを考える
・Coeiroink:テキスト読みあげ→Voicevoxはコードを指定すれば使える
・Notepad++:プログラム書く
・python:プログラム動作
・IrfanView:Chat GPTリロードのスクショに
*Pythonの開発環境設定も忘れずに
Pythonプラグ(参考サイト)
$ pip install requests
$ pip install pydub
$ pip install pyaudio
$ pip install pillow
$ python hello_ink.py
*ctrl+Cでpython対話終了
ファイルの保存先
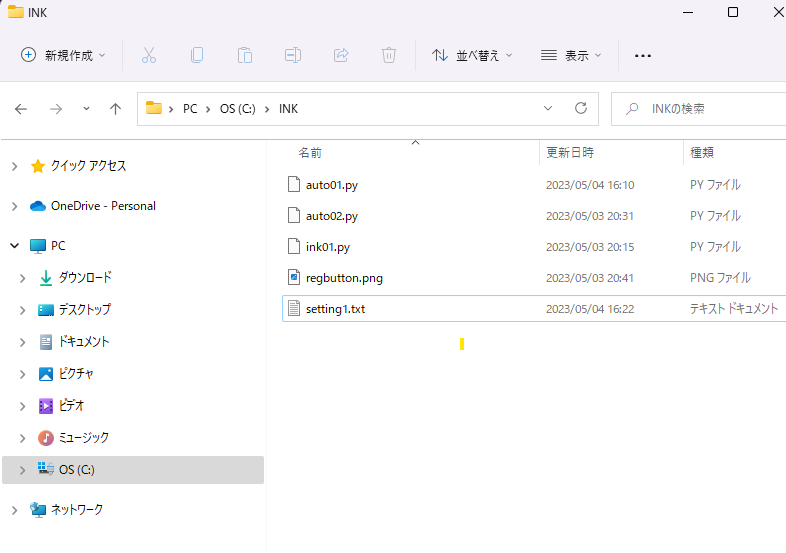
Cドライブ直下に「INK」というファイルを作成し、そこにNotepad++で書いたプログラムなど今回用いるファイルを格納する。INK意外にした場合、プログラムを書き換える必要がある(auto01.py)。
Anaconda Navigater
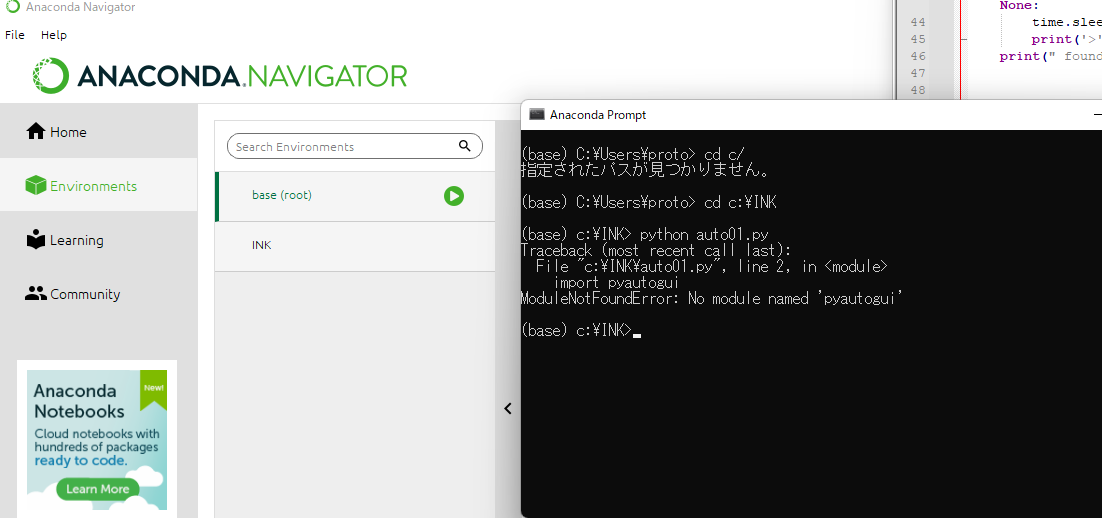
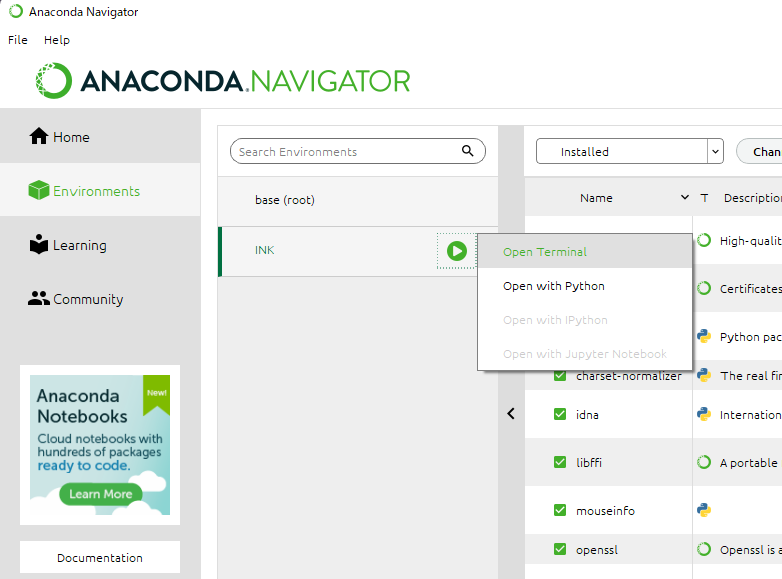
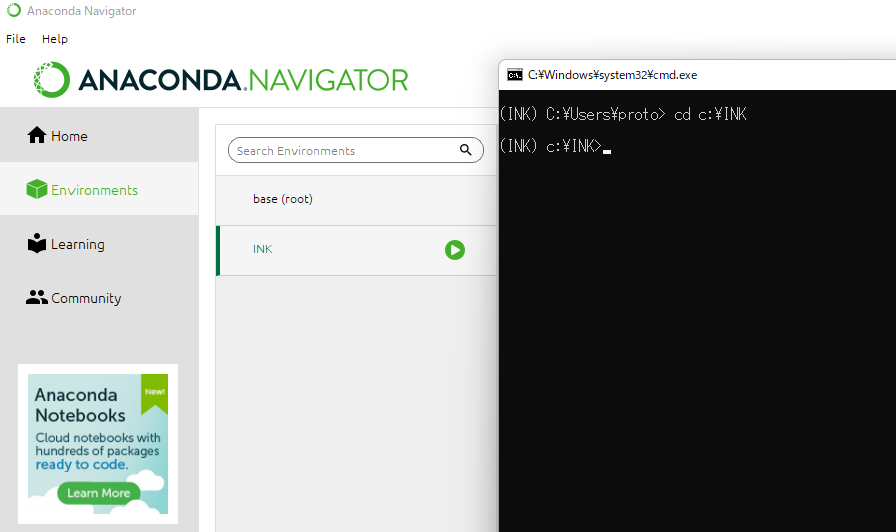
以前使用したのが保存されないのか、「Anaconda Navigater→INK」を選択してからでないと左画像のようにPrompt内で(base)のままでエラーをはかれる。
動作チェック
そもそもCoeiroinkに読んでもらえるかの動作チェックは下記プログラムから。9行目のspeaker_idからつくよみちゃんのタイプを切り替える(ID6など)。
import json
import requests
from pydub import AudioSegment, playback
# パラメータ
text = "こんにちは、つくよみちゃんです。よろしくお願いします。" # セリフ
text2="先日さ、友達とカラオケに行ったんだけど、その時の話がすごく面白かったんだよね。みんなで歌って楽しんでいたんだけど、途中で友達の一人が「誰か知らないけど、めちゃくちゃ上手い人が歌ってる!」って言い出したんだ。";
speaker_id = 1 # スピーカーID (0:つくよみちゃん)
# 音声合成のクエリの作成
response = requests.post(
"http://localhost:50031/audio_query",
params={
'text': text2,
'speaker': speaker_id,
'core_version': '0.0.0'
})
query = response.json()
# 音声合成のwavの生成
response = requests.post(
'http://localhost:50031/synthesis',
params={
'speaker': speaker_id,
'core_version': "0.0.0",
'enable_interrogative_upspeak': 'true'
},
data=json.dumps(query))
# wavの音声を再生
playback.play(AudioSegment(response.content,
sample_width=2, frame_rate=44100, channels=1))
実行するためのプログラム
この後に出てくる「setting01.txt」というChat GPT性格設定に使うテキスト文を元に、ヤンデレなり、ツンデレなり、思春期の娘など自分の好きなタイプに合わして会話できる。
注意点
・15行目:txtファイルの呼び出し
・21, 55, 69行目:カーソル位置
・38行目:画面のサイズを適当に→設定からMaxサイズを調べちょい減らした値
#auto01.py
import pyautogui
import pyperclip
import time
import json
import requests
from pydub import AudioSegment, playback
speaker_id = 0 # スピーカーID (0:つくよみちゃん)
#speaker_id = 1 # スピーカーID (まなノーマル)
config=""
##########################################
def copy_and_paste(text):
with open('C:/INK/setting1.txt', 'r',encoding='utf-8') as f:
config = f.read()
#print(config)
# インプット部分をクリックします
#pyautogui.moveTo(-905, 1370)
pyautogui.moveTo(361, 994)
pyautogui.click()
time.sleep(0.5)
#print(text)
print("_")
#入力する
pyperclip.copy(text)
pyautogui.hotkey('ctrl', 'v')
pyperclip.copy(config)
pyautogui.hotkey('ctrl', 'v')
pyautogui.press('enter')
#出力終了を待つ
time.sleep(1)
print('scan ',end='')
search_region = (0, 800, 900, 1070)
time.sleep(5)
while pyautogui.locateOnScreen('C:/INK/regbutton.png', region=search_region) == None:
time.sleep(0.1)
print('>',end='')
print(" found")
#下までスクロール
#time.sleep(1)
#pyautogui.scroll(-5000)
#time.sleep(1)
pyautogui.moveTo(856, 923)
pyautogui.click()
pyautogui.press('down')
pyautogui.press('down')
pyautogui.press('down')
pyautogui.press('down')
pyautogui.press('down')
pyautogui.press('down')
pyautogui.press('down')
pyautogui.press('down')
pyautogui.press('down')
pyautogui.press('down')
#x, y = -548, 1321
x, y = 856, 901
step=20
prev_clipboard = pyperclip.paste()
time.sleep(1)
for i in range(40):
y -= step
pyautogui.moveTo(x, y)
pyautogui.click()
# クリップボードのテキストを取得して表示する
clipboard_text = pyperclip.paste()
#print(y, clipboard_text)
if clipboard_text != prev_clipboard:
break
# 前回のクリップボードの内容を更新する
prev_clipboard = clipboard_text
print(clipboard_text)
pyautogui.moveTo(1791, 1220) #コンソールに復帰
pyautogui.click()
return clipboard_text
##########################################
def speakINK(msg):
# 音声合成のクエリの作成
response = requests.post(
"http://localhost:50031/audio_query",
params={
'text': msg,
'speaker': speaker_id,
'core_version': '0.0.0'
})
query = response.json()
# 音声合成のwavの生成
response = requests.post(
'http://localhost:50031/synthesis',
params={
'speaker': speaker_id,
'core_version': "0.0.0",
'enable_interrogative_upspeak': 'true'
},
data=json.dumps(query))
# wavの音声を再生
playback.play(AudioSegment(response.content,
sample_width=2, frame_rate=44100, channels=1))
##########################################
def main():
print("チャットをはじめます。q または quit で終了します。")
print("-"*50)
while True:
user = input("<あなた>\n")
if user == "q" or user == "quit":
print("お疲れ様でした")
break
else:
buf1=copy_and_paste(user)
speakINK(buf1)
# 現在のカーソル位置を取得
#current_position = pyautogui.position()
#print("現在のカーソル位置:", current_position)
#buf1=copy_and_paste("こんにちは")
#speakINK(buf1)
#image_location = pyautogui.locateOnScreen('C:/Users/Science/SELENIUM/clipicon.png')
#print(image_location )
if __name__ == "__main__":
main()
人格設定
Chat GPTの人格設定で、文頭に「。」がついていると読み込みやすい。「~の話し方」「~という感じで」とかアバウトでok.
。敬語は使わず、ヤンデレの話し方をして下さい。回答は50~100文字くらいで行ってください。口調は「なんで逃げるの?」とか「あなたのことは何でも知ってる」「私だけはずっと側にいるよ」といった感じで話してください。
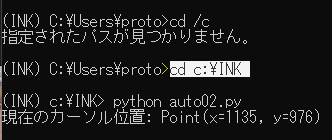
カーソル位置の取得
Pythonで勝手に文章のコピペ(コントロール)してもらうのに、座標を一つずつ教えてやらないといけないみたい。x, y座標を調べるためのプログラムは「auto02」。やり方は下記動画の通りマウスカーソルを合わして実行するだけ。座標の入力は「auto01」21, 55, 69行目。
#auto02.py
import pyautogui
import pyperclip
import time
# 現在のカーソル位置を取得
time.sleep(1)
current_position = pyautogui.position()
print("現在のカーソル位置:", current_position)
参考サイト(152)
・Pythonで画面操作
・Pythonでつくよみ