
今日はPythonから合成音声を操作します。
Anacondaのインストール
Python実行環境であるAnacondaのインストールを行う。とりあえずAnaconda3をダウンロードして道なりにインストール。終了すると、Anaconda PromptからPythonが実行できるようになる。インストールは、こちらのサイトが参考になる。インストールできたら、startメニューからAnaconda Promptを起動。Pythonコマンドで動作確認。Ctrl+Zで対話モード終了。
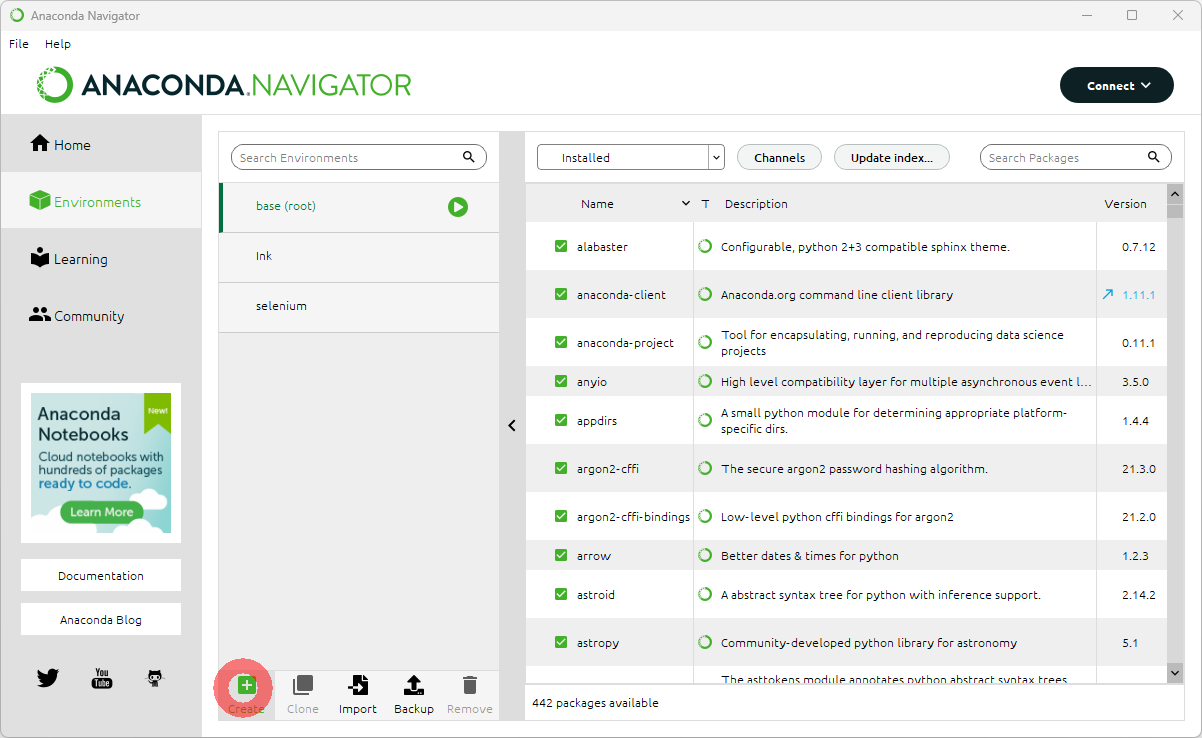
Anacondaで環境「INK」を作成する
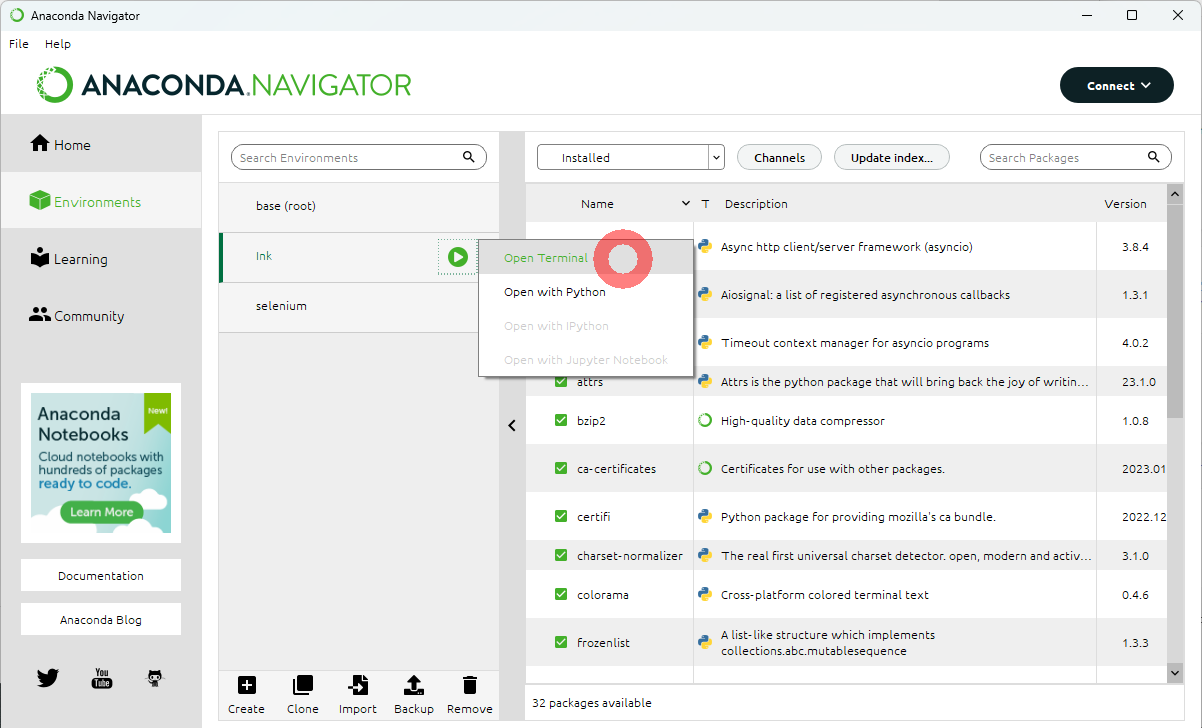
Anacondaがインストールできたら、EnvironmentからINKを作成し、Open terminalを実行してください。

作業フォルダを作成する
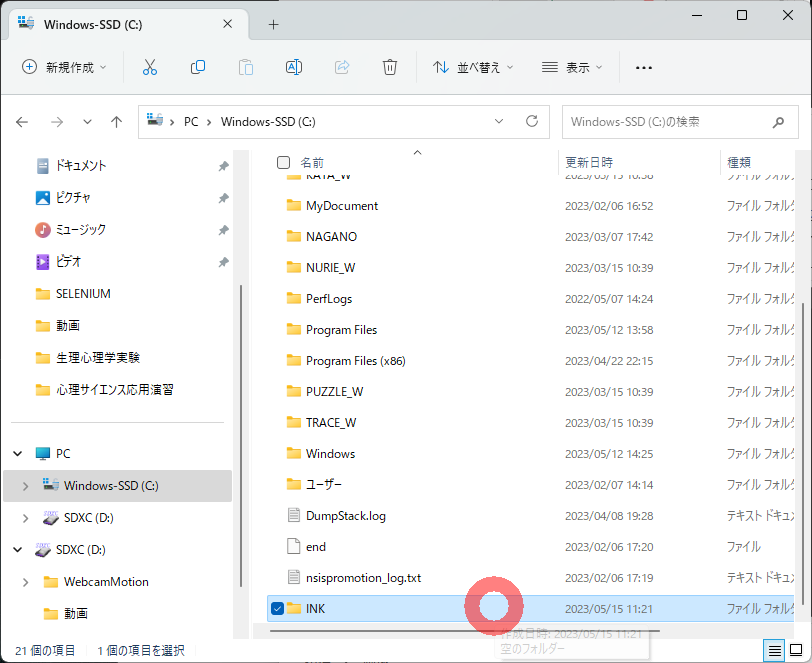
「Windows+E」を押して、ファイルエクスプローラを出したら、Cドライブに入って、Cドライブ直下に「INK」フォルダを作成しましょう。作成したら、ターミナルから「CD c:\INK」と入力して、c:\INKに移動しましょう。「python –version」と入力して、Pythonのバージョンが表示されればOKです。

Coeiroinkを呼ぶためにライブラリをインストールする
下記のコマンドを順に打ち込んで、requests、pydub、pyaudioの3つのライブラリをインストールします。ライブラリはネットワークインストールされるので、インターネット接続が必須です。
pip install requests
pip install pydub
pip install pyaudio
Pythonから合成音声を鳴らしてみる
いよいよ鳴らしてみましょう。下記のプログラムをc:\inkフォルダに「ink01.py」という名前で保存し、ターミナルから「python ink01.py」と打ち込み、実行してみましょう。合成音声を鳴らすには、Coeiroinkを起動しておく必要があります。スクリプトの編集はnotepad++がオススメです。
import json
import requests
from pydub import AudioSegment, playback
# パラメータ
text = "こんにちは、つくよみちゃんです。よろしくお願いします。"
speaker_id = 0 # スピーカーID (0:つくよみちゃん)
# 音声合成のクエリの作成
response = requests.post(
"http://localhost:50031/audio_query",
params={
'text': text,
'speaker': speaker_id,
'core_version': '0.0.0'
})
query = response.json()
# 音声合成のwavの生成
response = requests.post(
'http://localhost:50031/synthesis',
params={
'speaker': speaker_id,
'core_version': "0.0.0",
'enable_interrogative_upspeak': 'true'
},
data=json.dumps(query))
# wavの音声を再生
playback.play(AudioSegment(response.content,
sample_width=2, frame_rate=44100, channels=1))
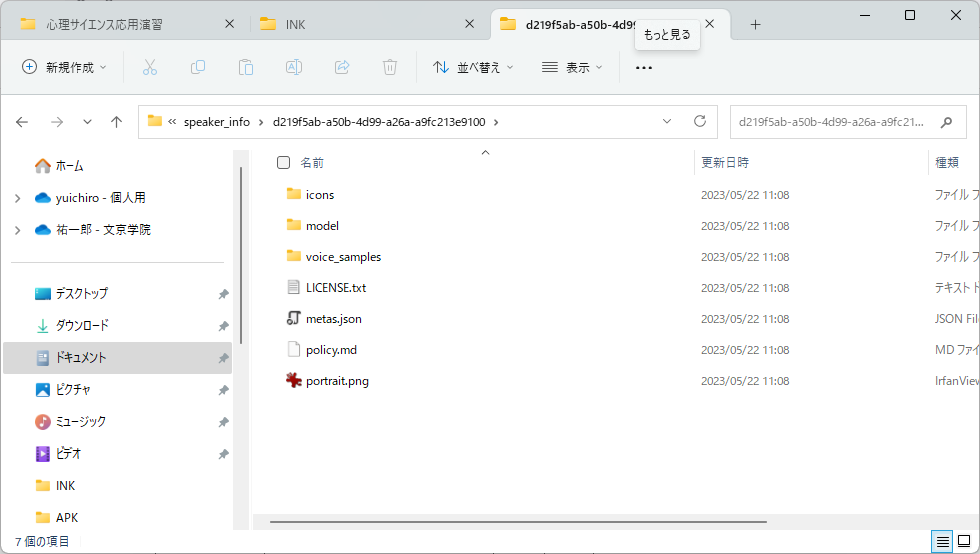
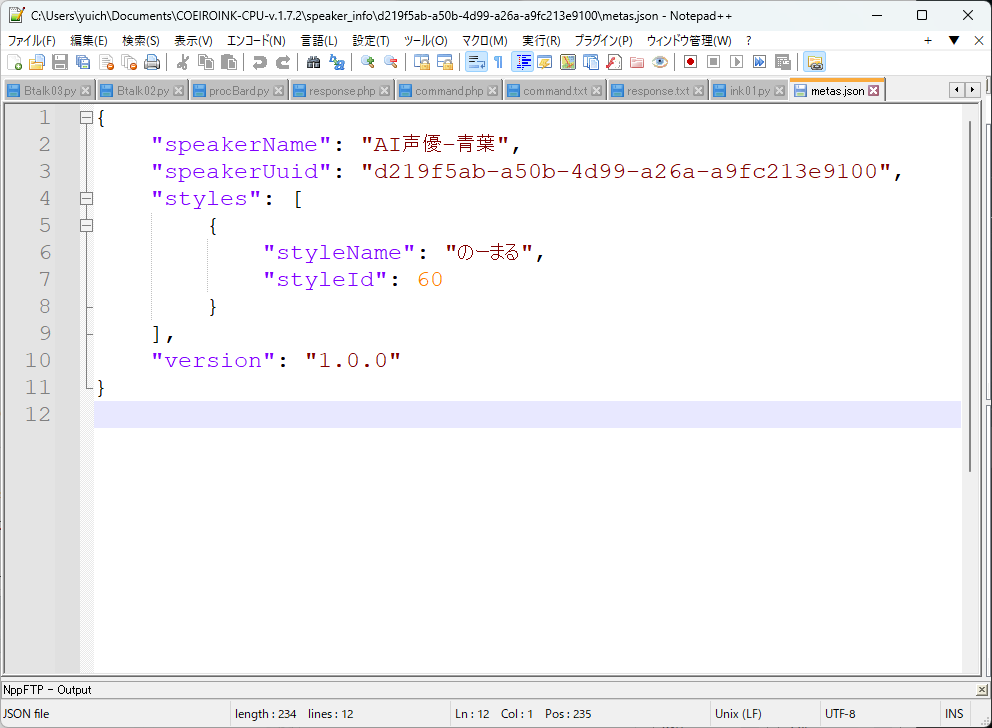
話者を変えるには、上記ソースコード中の「speaker_id 」を話者に応じた値に変更しましょう。各話者のspeaker_id は、coeiroinkのインストールフォルダの、speakerinfoフォルダの、各話者のフォルダ中にあるmetas.jsonに記載されています。

OpenAI APIを使う
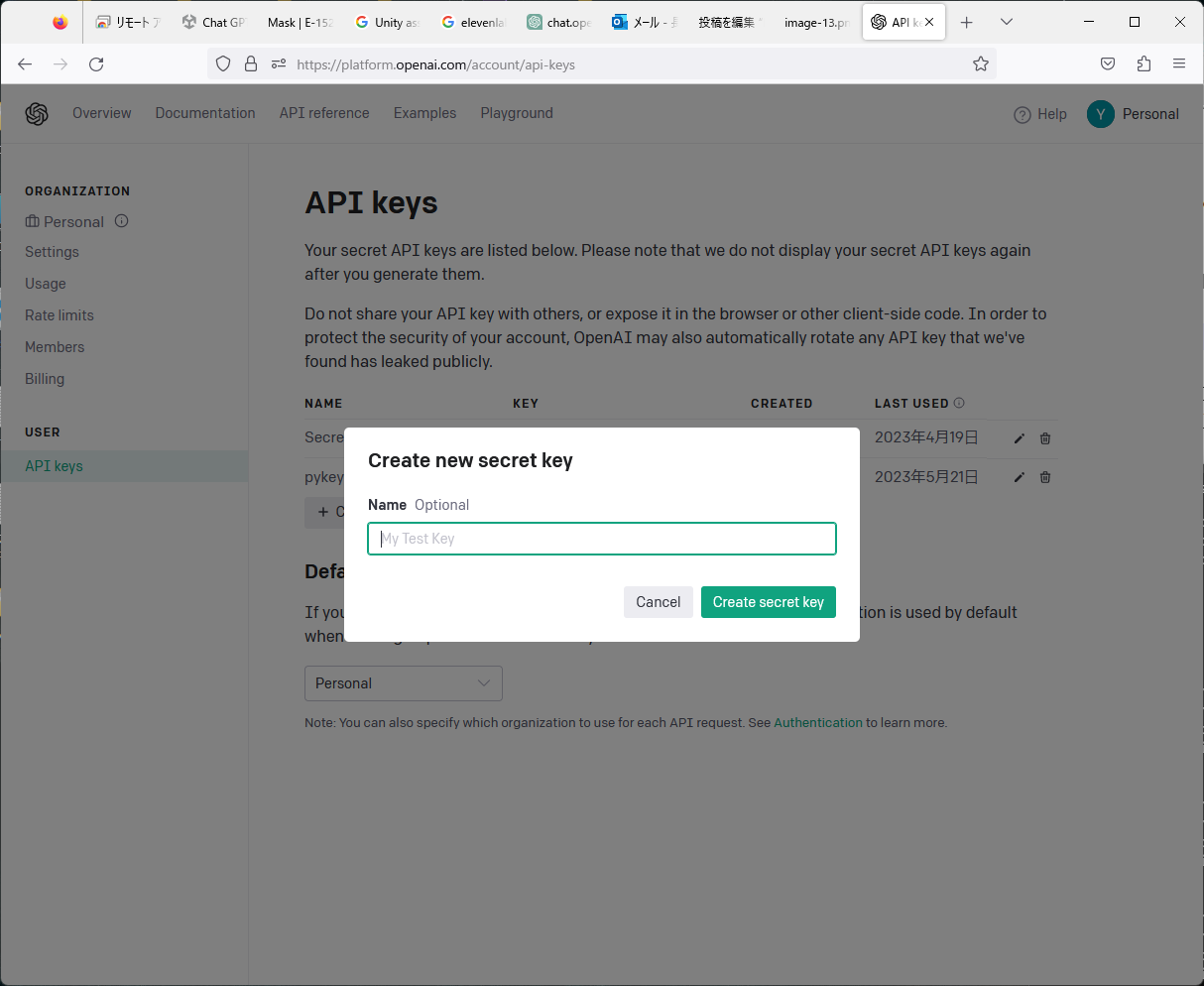
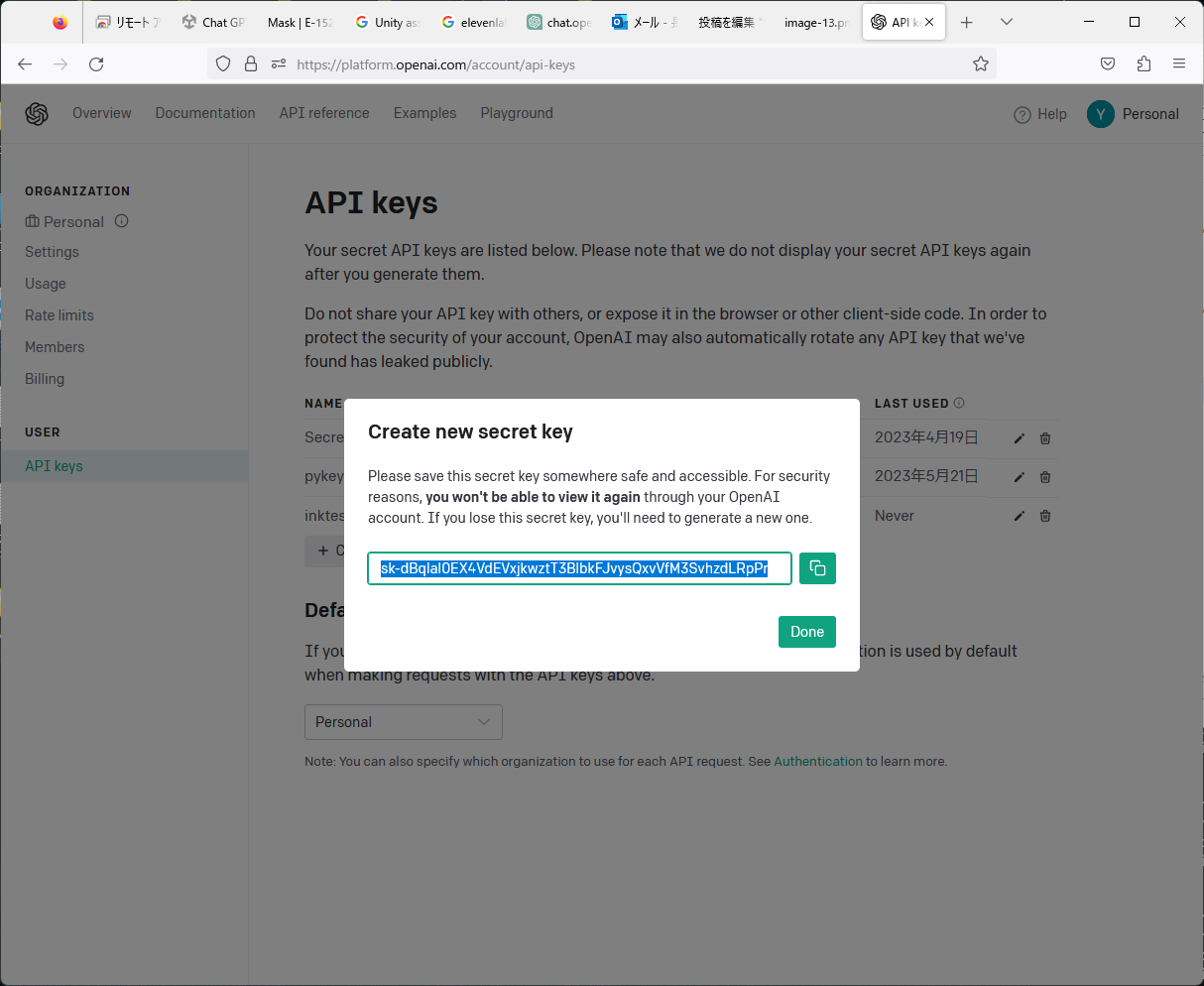
APIのページにアクセスし、GoogleIDでログインする。API keysのページから、「+create new secret key」を押します。キーの名前を入力し、エンターを押すと、シークレットキーが発行されます。シークレットキーをメモしてください。シークレットキーは、誰にも知らせないようにしてください。また、Organization>Settingのページから、「Organization ID」をコピーしておきましょう。



ChatGPTとPythonで会話する
ChatGPTを使うには、OpenAIのライブラリが必要です。コマンドラインから「pip install openai==0.27.4」と入力し、ライブラリをインストールしましょう。下記のプログラムをGPT1.pyという名前で、INKフォルダに保存し、「python GPT1.py」で実行してみましょう。apikeyは上記でメモしたキーを使いましょう。
import openai
openai.organization = ""
openai.api_key = ""
# =============================================================
# チャットボット関数
# =============================================================
def Ask_ChatGPT(message):
# 応答設定
completion = openai.ChatCompletion.create(
model = "gpt-3.5-turbo", # モデルを選択
messages = [{
"role":"user",
"content":message, # メッセージ
}],
max_tokens = 1024, # 生成する文章の最大単語数
n = 1, # いくつの返答を生成するか
stop = None, # 指定した単語が出現した場合、文章生成を打ち切る
temperature = 0.5, # 出力する単語のランダム性(0から2の範囲) 0であれば毎回返答内容固定
)
# 応答
response = completion.choices[0].message.content
# 応答内容出力
return response
# =============================================================
# チャットボット実行
# =============================================================
# 質問内容
message = "日本人の若者の特徴を教えてください"
# ChatGPT起動
res = Ask_ChatGPT(message)
# 出力
print(res)
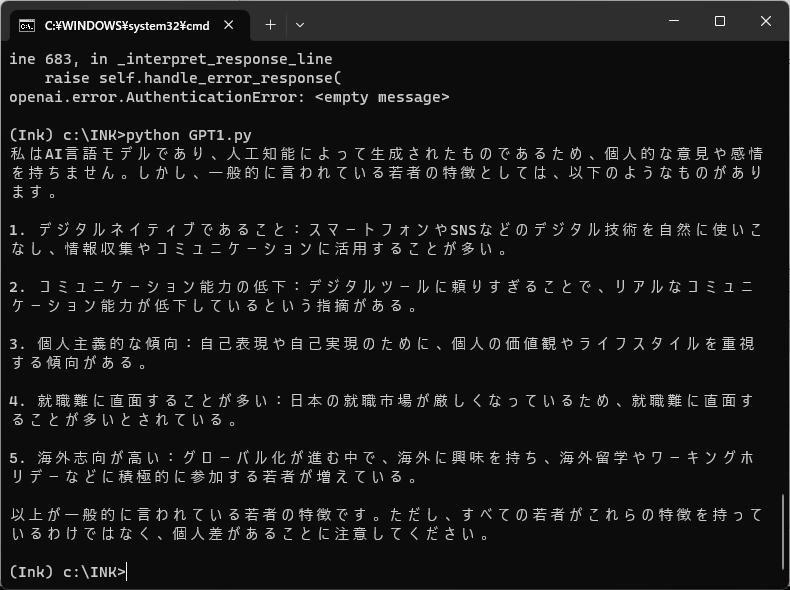
上記プログラムは、適切に実行されると、しばらく待った後に下記のような結果が表示されるはずです。質問を変えて、実行してみましょう。
チャットをする
下記のコードを「GPT2.py」という生で保存しましょう。このコードを実行することで、OpenAIのAPIとチャットができるようになります。
import openai
openai.organization = "org-ほげ"
openai.api_key = "sk-ほげ"
def main():
amount_tokens = 0
chat = []
setting = input("ChatGPTに設定を加えますか? y/n\n")
if setting == "y" or setting == "Y":
content = input("内容を入力してください。\n")
chat.append({"role": "system", "content": content})
print("チャットをはじめます。q または quit で終了します。")
print("-"*50)
while True:
user = input("<あなた>\n")
if user == "q" or user == "quit":
print(f"トークン数は{amount_tokens}でした。")
break
else:
chat.append({"role": "user", "content": user})
print("<ChatGPT>")
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",messages=chat
)
msg = response["choices"][0]["message"]["content"].lstrip()
amount_tokens += response["usage"]["total_tokens"]
print(msg)
chat.append({"role": "assistant", "content": msg})
if __name__ == "__main__":
main()
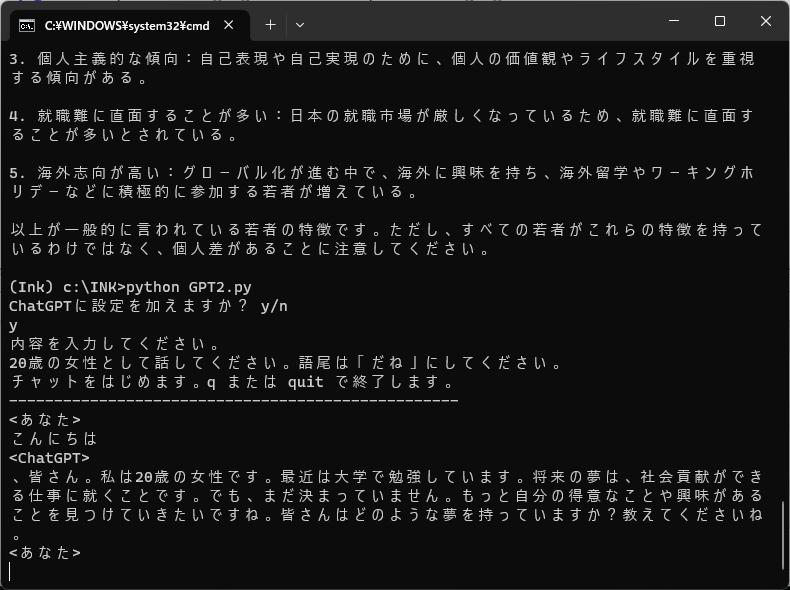
プログラムが起動すると、起動するとAIのキャラ設定を聞かれるので、yを押して、「20歳の女性として話してください」などの設定を記入してください。正しく動作すると、会話できるようになります。APIページのUSAGEから、残り金額を確認しながら会話してください。
CoeiroInkで会話内容を音声化してもらう
下記コードは、ChatGPTからの回答を音声化するものです。Coeiroinkが起動した状態で実行してください。ちなみに、Windows11の場合は「Windowsキー+H」で音声認識入力が可能です。音声会話を楽しんでみてください。
import openai
import json
import requests
from pydub import AudioSegment, playback
openai.organization = "ほげ"
openai.api_key = "ほげ"
speaker_id = 0 # スピーカーID (0:つくよみちゃん)
def main():
amount_tokens = 0
chat = []
setting = input("ChatGPTに設定を加えますか? y/n\n")
if setting == "y" or setting == "Y":
content = input("内容を入力してください。\n")
chat.append({"role": "system", "content": content})
print("チャットをはじめます。q または quit で終了します。")
print("-"*50)
while True:
user = input("<あなた>\n")
if user == "q" or user == "quit":
print(f"トークン数は{amount_tokens}でした。")
break
else:
chat.append({"role": "user", "content": user})
print("<ChatGPT>")
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",messages=chat
)
msg = response["choices"][0]["message"]["content"].lstrip()
amount_tokens += response["usage"]["total_tokens"]
print(msg)
playsound(msg)
chat.append({"role": "assistant", "content": msg})
def playsound(text):
# 音声合成のクエリの作成
response = requests.post(
"http://localhost:50031/audio_query",
params={
'text': text,
'speaker': speaker_id,
'core_version': '0.0.0'
})
query = response.json()
# 音声合成のwavの生成
response = requests.post(
'http://localhost:50031/synthesis',
params={
'speaker': speaker_id,
'core_version': "0.0.0",
'enable_interrogative_upspeak': 'true'
},
data=json.dumps(query))
# wavの音声を再生
playback.play(AudioSegment(response.content,
sample_width=2, frame_rate=44100, channels=1))
if __name__ == "__main__":
main()
会話用修正プログラムその1
import openai
import json
import requests
from pydub import AudioSegment, playback
openai.organization = "org-ほげ"
openai.api_key = "sk-ほげ"
speaker_id = 0 #つくよみちゃんれいせい
speaker_id = 90 #リリンちゃん
def main():
amount_tokens = 0
chat = []
option="敬語は使わず、馬鹿っぽい話し方をしてください。回答は50文字くらいで行ってください。ネガティブで攻撃的な性格です。「えーそんなんあったかなぁ」、「だめじゃん、もうやめればいいのに」、「いいかげんにしろよ」といった口調で話してください。一人称は「アタシ」でお願いします。";
print("チャットをはじめます。q または quit で終了します。")
print("-"*50)
while True:
user = input("<あなた>\n")
user2=user+option
if user == "q" or user == "quit":
print(f"トークン数は{amount_tokens}でした。")
break
else:
chat.append({"role": "user", "content": user2})
print("<ChatGPT>")
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",messages=chat
)
msg = response["choices"][0]["message"]["content"].lstrip()
amount_tokens += response["usage"]["total_tokens"]
print(msg)
playsound(msg)
chat.append({"role": "assistant", "content": msg})
def playsound(text):
# 音声合成のクエリの作成
response = requests.post(
"http://localhost:50031/audio_query",
params={
'text': text,
'speaker': speaker_id,
'core_version': '0.0.0'
})
query = response.json()
# 音声合成のwavの生成
response = requests.post(
'http://localhost:50031/synthesis',
params={
'speaker': speaker_id,
'core_version': "0.0.0",
'enable_interrogative_upspeak': 'true'
},
data=json.dumps(query))
# wavの音声を再生
playback.play(AudioSegment(response.content,
sample_width=2, frame_rate=44100, channels=1))
if __name__ == "__main__":
main()
GPT4oを使った会話プログラムです。GPT5.pyという名前で保存してください。
#GPT5.py
import openai
import json
import requests
from pydub import AudioSegment, playback
openai.organization = "org-ほげ"
openai.api_key = "sk-ほげ"
speaker_id = 0 # 0:つくよみちゃんれいせい
def main():
amount_tokens = 0
chat = []
systemsetting="20歳の女子大学生として話してください。ポジティブな正確で、親しみやすい話し方をします。「◯◯かな」、「◯◯かも」、「そうだね」、「本当だね!」などのような話し方をします。";
chat.append({"role": "system", "content": systemsetting})
option="";
print("チャットをはじめます。q または quit で終了します。")
print("-"*50)
while True:
user = input("<あなた>\n")
user2=user+option
if user == "q" or user == "quit":
print(f"トークン数は{amount_tokens}でした。")
break
else:
chat.append({"role": "user", "content": user2})
print("<ChatGPT>")
response = openai.ChatCompletion.create(
model="gpt-4o",messages=chat
)
msg = response["choices"][0]["message"]["content"].lstrip()
amount_tokens += response["usage"]["total_tokens"]
print(msg)
playsound(msg)
chat.append({"role": "assistant", "content": msg})
def playsound(text):
# 音声合成のクエリの作成
response = requests.post(
#"http://localhost:50031/audio_query",
"https://fc49-150-249-222-29.ngrok-free.app/audio_query",
params={
'text': text,
'speaker': speaker_id,
'core_version': '0.0.0'
})
query = response.json()
# 音声合成のwavの生成
response = requests.post(
#'http://localhost:50031/synthesis',
"https://fc49-150-249-222-29.ngrok-free.app/synthesis",
params={
'speaker': speaker_id,
'core_version': "0.0.0",
'enable_interrogative_upspeak': 'true'
},
data=json.dumps(query))
# wavの音声を再生
playback.play(AudioSegment(response.content,
sample_width=2, frame_rate=44100, channels=1))
if __name__ == "__main__":
main()