「未分類」カテゴリーアーカイブ
心理サイエンス
TinkerCad
Unityでチャットボットを作る
必要ファイル一式
プログラムとキャラクタファイル一式をデスクトップに解凍しておきましょう。また,Mixamoでアニメーションの付与されたFBXファイルを作成しておきましょう。
(サイト改竄の被害にあい現在復旧中です。)
ChatGPT:
using System;
using System.Collections.Generic;
using System.Text;
using UnityEngine;
using UnityEngine.Networking;
public class TestGPT : MonoBehaviour
{
#region 必要なクラスの定義など
[System.Serializable]
public class MessageModel
{
public string role;
public string content;
}
[System.Serializable]
public class CompletionRequestModel
{
public string model;
public List<MessageModel> messages;
}
[System.Serializable]
public class ChatGPTRecieveModel
{
public string id;
public string @object;
public int created;
public Choice[] choices;
public Usage usage;
[System.Serializable]
public class Choice
{
public int index;
public MessageModel message;
public string finish_reason;
}
[System.Serializable]
public class Usage
{
public int prompt_tokens;
public int completion_tokens;
public int total_tokens;
}
}
#endregion
private MessageModel assistantModel = new()
{
role = "system",
content = "あなたは冒険者ギルドの受付です。"
};
public string apiKey = "your_apiKey";
public string GPTmodel = "gpt-4o";
private List<MessageModel> communicationHistory = new();
void Start()
{
communicationHistory.Add(assistantModel);
MessageSubmit("はじめまして");
}
private void Communication(string newMessage, Action<MessageModel> result)
{
Debug.Log(newMessage);
communicationHistory.Add(new MessageModel()
{
role = "user",
content = newMessage
});
var apiUrl = "https://api.openai.com/v1/chat/completions";
var jsonOptions = JsonUtility.ToJson(
new CompletionRequestModel()
{
model = GPTmodel,
messages = communicationHistory
}, true);
var headers = new Dictionary<string, string>
{
{"Authorization", "Bearer " + apiKey},
{"Content-type", "application/json"},
{"X-Slack-No-Retry", "1"}
};
var request = new UnityWebRequest(apiUrl, "POST")
{
uploadHandler = new UploadHandlerRaw(Encoding.UTF8.GetBytes(jsonOptions)),
downloadHandler = new DownloadHandlerBuffer()
};
foreach (var header in headers)
{
request.SetRequestHeader(header.Key, header.Value);
}
var operation = request.SendWebRequest();
operation.completed += _ =>
{
if (operation.webRequest.result == UnityWebRequest.Result.ConnectionError ||
operation.webRequest.result == UnityWebRequest.Result.ProtocolError)
{
Debug.LogError(operation.webRequest.error);
throw new Exception();
}
else
{
var responseString = operation.webRequest.downloadHandler.text;
var responseObject = JsonUtility.FromJson<ChatGPTRecieveModel>(responseString);
communicationHistory.Add(responseObject.choices[0].message);
Debug.Log(responseObject.choices[0].message.content);
}
request.Dispose();
};
}
public void MessageSubmit(string sendMessage)
{
Communication(sendMessage, (result) =>
{
Debug.Log(result.content);
});
}
}
SimpleChat
InputField1の内容をgpt4に送って,返答内容をInputField2に格納するチャットスクリプト。ボタンにMessageSubmit関数をセットする必要がある。
using System;
using System.Collections.Generic;
using System.Text;
using UnityEngine;
using UnityEngine.Networking;
using UnityEngine.UI;
public class SimpleChat : MonoBehaviour
{
#region 必要なクラスの定義など
[System.Serializable]
public class MessageModel
{
public string role;
public string content;
}
[System.Serializable]
public class CompletionRequestModel
{
public string model;
public List<MessageModel> messages;
}
[System.Serializable]
public class ChatGPTRecieveModel
{
public string id;
public string @object;
public int created;
public Choice[] choices;
public Usage usage;
[System.Serializable]
public class Choice
{
public int index;
public MessageModel message;
public string finish_reason;
}
[System.Serializable]
public class Usage
{
public int prompt_tokens;
public int completion_tokens;
public int total_tokens;
}
}
#endregion
public InputField IF1; //入力用InputField
public InputField IF2; //出力用InputField
public string apiKey = "your_apiKey";
[SerializeField, TextArea(3, 10)] public string systemstr = "あなたはアラスカ在住の女子高校生です。";
/*
あなたはアイオワ州在住の陸軍兵士です。
ちょっとぶっきらぼうだけと本当は優しい性格で,少し荒っぽい話し方で話します。
negative-positiveでいうとややネガティブな性格です一人称は「オレ」です。
「◯◯だよな」「◯◯だろうよ」「わかんねぇな」「そういうこともあるさ」といった口調で話します。
相手の悩みをほっておけず、気にかけて、いろいろ質問紙てくる。相談にのってくれ、助言をくれる。
平均100文字、標準偏差50文字、最大300文字程度で話してください。
*/
// voicevox連携部分
// public TestVVOX myVVOX;
private MessageModel assistantModel = new()
{
role = "system",
content = "あなたはアラスカ在住の女子高校生です。"
};
private List<MessageModel> communicationHistory = new();
void Start()
{
assistantModel.content = systemstr;
}
public void Update()
{
}
private void Communication(string newMessage, Action<MessageModel> result)
{
communicationHistory.Add(new MessageModel()
{
role = "user",
content = newMessage
});
var apiUrl = "https://api.openai.com/v1/chat/completions";
var jsonOptions = JsonUtility.ToJson(
new CompletionRequestModel()
{
model = "gpt-4o",
messages = communicationHistory
}, true);
var headers = new Dictionary<string, string>
{
{"Authorization", "Bearer " + apiKey},
{"Content-type", "application/json"},
{"X-Slack-No-Retry", "1"}
};
var request = new UnityWebRequest(apiUrl, "POST")
{
uploadHandler = new UploadHandlerRaw(Encoding.UTF8.GetBytes(jsonOptions)),
downloadHandler = new DownloadHandlerBuffer()
};
foreach (var header in headers)
{
request.SetRequestHeader(header.Key, header.Value);
}
var operation = request.SendWebRequest();
operation.completed += _ =>
{
if (operation.webRequest.result == UnityWebRequest.Result.ConnectionError ||
operation.webRequest.result == UnityWebRequest.Result.ProtocolError)
{
Debug.LogError(operation.webRequest.error);
throw new Exception();
}
else
{
var responseString = operation.webRequest.downloadHandler.text;
var responseObject = JsonUtility.FromJson<ChatGPTRecieveModel>(responseString);
communicationHistory.Add(responseObject.choices[0].message);
Debug.Log("assistant:" + responseObject.choices[0].message.content);
IF2.text = responseObject.choices[0].message.content;
// voicevoxで音声合成
//if (myVVOX != null) myVVOX.procTTS(responseObject.choices[0].message.content);
}
request.Dispose();
};
}
public void MessageSubmit()
{
Debug.Log("user:" + IF1.text);
communicationHistory.Add(assistantModel);
Communication(IF1.text, (result) =>
{
//Debug.Log("mes3:"+result.content);
});
}
}
TestVVOX
VoiceVOXをUnityから呼び出すサンプルプログラム。SpeakerIDはここを参照。ローカル環境でVoiceVOXを起動しておく必要がある。
using System;
using System.Collections;
using UnityEngine;
using UnityEngine.Networking;
public class TestVVOX : MonoBehaviour
{
private VoiceVoxConnection _voiceVoxConnection;
private AudioSource audioSource;
public string VVOXurl = "http://127.0.0.1:50021"; // ローカル動作のVVOXのURL;
public int speakerID = 3; //ずんだもん
public string testMessage = "こんにちは!ずんだもんです!";
// Start is called before the first frame update
void Start()
{
audioSource = gameObject.GetComponent<AudioSource>();
_voiceVoxConnection = new VoiceVoxConnection();
_voiceVoxConnection._speaker = speakerID;
_voiceVoxConnection._voiceVoxUrl = VVOXurl;
if (testMessage.Length>0) {
// コルーチンを使用して非同期処理を呼び出す
StartCoroutine(TranslateTextToAudioClip(testMessage));
}
}
private IEnumerator TranslateTextToAudioClip(string text)
{
AudioClip clip = null;
// VoiceVoxConnectionのコルーチンを実行
yield return StartCoroutine(_voiceVoxConnection.TranslateTextToAudioClip(text, result =>
{
clip = result;
}));
if (clip != null)
{
audioSource.clip = clip;
audioSource.Play();
}
else
{
Debug.LogError("AudioClip is null");
}
}
}
public class VoiceVoxConnection
{
public string _voiceVoxUrl;
public int _speaker;
public VoiceVoxConnection()
{
}
public IEnumerator TranslateTextToAudioClip(string text, Action<AudioClip> callback)
{
string queryJson = null;
// Audio Query を取得
yield return SendAudioQuery(text, result =>
{
queryJson = result;
});
if (string.IsNullOrEmpty(queryJson))
{
Debug.LogError("Failed to get audio query");
callback(null);
yield break;
}
// Audio Clip を取得
yield return GetAudioClip(queryJson, clip =>
{
callback(clip);
});
}
private IEnumerator SendAudioQuery(string text, Action<string> callback)
{
var form = new WWWForm();
using UnityWebRequest request = UnityWebRequest.Post($"{_voiceVoxUrl}/audio_query?text={text}&speaker={_speaker}", form);
yield return request.SendWebRequest();
if (request.result == UnityWebRequest.Result.ConnectionError || request.result == UnityWebRequest.Result.ProtocolError)
{
Debug.LogError(request.error);
callback(null);
}
else
{
callback(request.downloadHandler.text);
}
}
private IEnumerator GetAudioClip(string queryJson, Action<AudioClip> callback)
{
var url = $"{_voiceVoxUrl}/synthesis?speaker={_speaker}";
using UnityWebRequest req = new UnityWebRequest(url, "POST")
{
uploadHandler = new UploadHandlerRaw(System.Text.Encoding.UTF8.GetBytes(queryJson)),
downloadHandler = new DownloadHandlerBuffer()
};
req.SetRequestHeader("Content-Type", "application/json");
yield return req.SendWebRequest();
if (req.result == UnityWebRequest.Result.ConnectionError || req.result == UnityWebRequest.Result.ProtocolError)
{
Debug.LogError(req.error);
callback(null);
}
else
{
callback(WavUtility.ToAudioClip(req.downloadHandler.data));
}
}
public static AudioClip ToAudioClip(byte[] data)
{
// ヘッダー解析
int channels = data[22];
int frequency = BitConverter.ToInt32(data, 24);
int length = data.Length - 44;
float[] samples = new float[length / 2];
// 波形データ解析
for (int i = 0; i < length / 2; i++)
{
short value = BitConverter.ToInt16(data, i * 2 + 44);
samples[i] = value / 32768f;
}
// AudioClipを作成
AudioClip audioClip = AudioClip.Create("AudioClip", samples.Length, channels, frequency, false);
audioClip.SetData(samples, 0);
return audioClip;
}
}
キャラクターの読み込みとリップシンクの設定
mixamoからアニメーションをダウンロードし,uLipSyncでリップシンクを追加する。
PythonでChatGPTを使う
Anacondaのインストール
Python実行環境であるAnacondaのインストールを行う。とりあえずAnaconda3をダウンロードして道なりにインストール。終了すると、Anaconda PromptからPythonが実行できるようになる。インストールは、こちらのサイトが参考になる。インストールできたら、startメニューからAnaconda Promptを起動。Pythonコマンドで動作確認。Ctrl+Zで対話モード終了。テキストエディタはNotepad++を推奨します。
GPT01/最低限のコード
文章作成を行うための最低限のコード。Temperatureが指定できる。
#GPT01.py
#GPT4を使って文章生成を行う最低限のコード
from openai import OpenAI
client = OpenAI(api_key="sk-hogehoge")
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "あなたは中学生男子です"},
{"role": "user", "content": "呪術廻戦の好きなキュラクターを200文字で伝えてください。"}
],
#temperature=0.1文章が一貫性の高い回答
#temperature=0.9より創造的で予想外な回答
temperature=0.7
)
# 日本語の文字列部分だけを取得
response_text = completion.choices[0].message.content
print(response_text)
GPT02/使用したトークンの取得
文章生成に使用したトークンの数を表示してくれる。
#GPT02.py
#GPT4を使って文章生成を行い消費したトークンを表示
from openai import OpenAI
client = OpenAI(api_key="sk-hogehoge")
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "あなたは大学図書館の優秀な受付です"},
{"role": "user", "content": "初めて図書館に来た大学生に、図書館の魅力を200文字で伝えてください。"}
],
temperature=0.7
)
# 日本語の文字列部分だけを取得
response_text = completion.choices[0].message.content
print(response_text)
# 消費したトークン数を表示
total_tokens = completion.usage.total_tokens
prompt_tokens = completion.usage.prompt_tokens
completion_tokens = completion.usage.completion_tokens
print(f"消費したトークン数: 合計 {total_tokens}, プロンプト {prompt_tokens}, 応答 {completion_tokens}")
Chat01/チャット用スクリプト
人格を設定して会話を行うことができる。
#Chat01.py
#設定した人格に基づいて、チャットを行うスクリプト。
from openai import OpenAI
client = OpenAI(api_key="sk-hogehoge")
personality = "あなたは、埼玉県内の大学に通う男子大学2年生です。所属学科は心理学科です。一人称は「僕」、二人称は「きみ」を使います。明るく気さくな感じで話します。「〇〇だよな」「〇〇だな」「〇〇だろ?」「〇〇だと思う」などの語尾を使って話します。"
# 初期設定
messages = [
{"role": "system", "content": personality}
]
print("模擬人格と会話を始めます。'終了'と入力すると終了します。")
while True:
# ユーザーの入力を受け取る
user_input = input("user: ")
# 終了コマンド
if user_input.strip() == "終了":
print("会話を終了します。")
break
# ユーザー発言を保存
messages.append({"role": "user", "content": user_input})
# 会話履歴を最新20件に制限
if len(messages) > 21: # 21 = systemメッセージ + 過去20回の履歴
messages.pop(1) # 最初のユーザーかアシスタントの履歴を削除
# OpenAI APIにリクエスト
completion = client.chat.completions.create( # 修正箇所
model="gpt-4o",
messages=messages,
temperature=0.7
)
# アシスタントの応答を取得
assistant_response = completion.choices[0].message.content
print(f"assistant: {assistant_response}")
# アシスタントの応答を保存
messages.append({"role": "assistant", "content": assistant_response})
VVOX01/合成音声を作成する最低限のスクリプト
まずはvoicevoxをインストールしましょう。ローカルで実行中のvoicevoxにむかってテキストを送り込み,合成音声として再生してもらいます。voicevoxのspeakerIDはこちらを参照。ライブラリを以下のコマンドでインストールしましょう。
#VVOX01.py
#ローカルで起動したvoicevoxに、pythonから文字を送って合成音声を再生するスクリプト。
import requests
import json
from pydub import AudioSegment, playback
HOSTNAME='http://localhost:50021'
speaker = 3 #ずんだもん
msg="こんにちは,ずんだもんです!"
def playsound(text):
# audio_query (音声合成用のクエリを作成するAPI)
res1 = requests.post(HOSTNAME + '/audio_query',
params={'text': text, 'speaker': speaker})
# synthesis (音声合成するAPI)
res2 = requests.post(HOSTNAME + '/synthesis',
params={'speaker': speaker},
data=json.dumps(res1.json()))
# wavの音声を再生
playback.play(AudioSegment(res2.content,
sample_width=2, frame_rate=44100, channels=1))
playsound(msg)
Chat02/合成音声でAIとチャットを行うスクリプト
チャットスクリプトと合成音声スクリプトを統合したもの。
#Chat02.py
#設定した人格に基づいて、チャットを行い、AIの返答を合成音声で返答するスクリプト。
from openai import OpenAI
import requests
import json
from pydub import AudioSegment, playback
# OpenAI API設定
client = OpenAI(api_key="sk-hogehoge")
# VoiceVox設定
HOSTNAME = 'http://localhost:50021'
speaker = 13 # 青山龍星
def playsound(text):
"""VoiceVoxで音声合成して再生する"""
# audio_query (音声合成用のクエリを作成するAPI)
res1 = requests.post(HOSTNAME + '/audio_query',
params={'text': text, 'speaker': speaker})
# synthesis (音声合成するAPI)
res2 = requests.post(HOSTNAME + '/synthesis',
params={'speaker': speaker},
data=json.dumps(res1.json()))
# wavの音声を再生
playback.play(AudioSegment(res2.content,
sample_width=2, frame_rate=24000, channels=1))
# AIの人格設定
personality = "あなたは、アイオワ州在住の陸軍兵士です。一人称は「おれ」、二人称は「おまえ」を使います。「〇〇だよな」「〇〇だな」「〇〇だろ?」「〇〇だと思う」などの語尾を使って話します。ぶっきらぼうだけど、本当は優しい性格で、ユーザーの会話を掘り下げ、悩み相談にのってくれる。"
# 初期設定
messages = [
{"role": "system", "content": personality}
]
print("模擬人格と会話を始めます。'終了'と入力すると終了します。")
while True:
# ユーザーの入力を受け取る
user_input = input("user: ")
# 終了コマンド
if user_input.strip() == "終了":
print("会話を終了します。")
break
# ユーザー発言を保存
messages.append({"role": "user", "content": user_input})
# 会話履歴を最新20件に制限
if len(messages) > 21:
messages.pop(1)
# OpenAI APIにリクエスト
completion = client.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=0.7
)
# アシスタントの応答を取得
assistant_response = completion.choices[0].message.content
print(f"assistant: {assistant_response}")
# アシスタントの応答を保存
messages.append({"role": "assistant", "content": assistant_response})
# VoiceVoxで音声合成&再生
playsound(assistant_response)
ChatGPT:


#GPT4V.py
#画像を読み込んで、説明を行うスクリプト。
import base64
from pathlib import Path
from openai import OpenAI
client = OpenAI(api_key="sk-hogehoge")
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
image_path = "picture2.jpg"
base64_image = encode_image(image_path)
file_extension = Path(image_path).suffix
file_extension_without_dot = file_extension[1:]
url = f"data:image/{file_extension_without_dot};base64,{base64_image}"
response = client.chat.completions.create(
model="gpt-4.1-mini",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "どのような状況か300文字くらいで説明してください。季節も推測してください。",
},
{
"type": "image_url",
"image_url": {
"url": url,
},
},
],
}
],
max_tokens=1000,
)
print(response.choices[0].message.content)
神経・生理心理学(4)
神経・生理心理学(6)
PythonでFitbit(3)
本ページの概要
Fitbitで測定したHRV(心拍変動),RHR(安静時心拍)を1週間分取得する方法を学習します。
PythonでHRV(心拍変動)・RHR(安静時心拍)データを取得する
下記のプログラム「getWeekHRV.py」をエディタで開発ディレクトリに作成し,USER_ID ,CLIENT_SECRET をセットします。さらにプログラム末尾の,
today=date(2025, 10, 15)
for var in range(0, 7):
部分をセットします。ターミナル上で,
python getWeekHRV.py
と入力し,実行する。正常に動作すると,
「23QTVF_HRV.csv」のようなファイルが開発ディレクトリに作成される。「getWeekRHR.py」も同様に使用する。
#getWeekHRV.py
import sys
import fitbit
import gather_keys_oauth2 as Oauth2
from datetime import datetime, timedelta
import json
from datetime import datetime, date, timedelta
print('getWeekHRV')
USER_ID = "hogehoge"
CLIENT_SECRET = "hogehoge"
def requestFitbit(DATE):
global auth2_client
# APIエンドポイントを使用してHRVデータを取得
hrv_data = auth2_client.make_request(f'https://api.fitbit.com/1/user/-/hrv/date/{DATE}.json')
OUTPUT_FILE = USER_ID + "_HRV.csv"
with open(OUTPUT_FILE, 'a') as csv_file:
csv_file.write(f"{DATE},")
if "hrv" in hrv_data and len(hrv_data["hrv"]) > 0:
hrv_info = hrv_data["hrv"][0] # リストの最初の要素を取得
csv_file.write(f"{hrv_info['value']['dailyRmssd']},{hrv_info['value']['deepRmssd']}\n")
else:
csv_file.write("No HRV data\n")
def writeindex():
OUTPUT_FILE = USER_ID + "_HRV.csv"
with open(OUTPUT_FILE, 'w') as csv_file:
csv_file.write("date,dailyRmssd,deepRmssd\n")
# トークンの取得
server = Oauth2.OAuth2Server(USER_ID, CLIENT_SECRET)
server.browser_authorize()
ACCESS_TOKEN = str(server.fitbit.client.session.token['access_token'])
REFRESH_TOKEN = str(server.fitbit.client.session.token['refresh_token'])
print(ACCESS_TOKEN)
print(REFRESH_TOKEN)
# 認証
auth2_client = fitbit.Fitbit(USER_ID, CLIENT_SECRET, oauth2=True, access_token=ACCESS_TOKEN, refresh_token=REFRESH_TOKEN)
# インデックスの書き込み
writeindex()
# HRVデータのリクエスト
#today = datetime.today()
today = date(2025, 10, 15)
for var in range(0, 7):
stamp = datetime.strftime(today - timedelta(days=var), '%Y-%m-%d')
print(f"target: {stamp}", end=' ')
requestFitbit(stamp)
# getWeekRHR.py
import sys
import fitbit
import gather_keys_oauth2 as Oauth2
from datetime import datetime, timedelta, date
print('getWeekRHR')
USER_ID = "hogehoge"
CLIENT_SECRET = "hogehoge"
def requestFitbit(DATE):
"""
指定日の安静時心拍数を取得して CSV に追記する。
"""
global auth2_client
# RHR は activities/heart エンドポイントから取得
rhr_data = auth2_client.make_request(
f'https://api.fitbit.com/1/user/-/activities/heart/date/{DATE}/1d.json'
)
OUTPUT_FILE = USER_ID + "_RHR.csv"
with open(OUTPUT_FILE, 'a', encoding='utf-8') as csv_file:
csv_file.write(f"{DATE},")
if ("activities-heart" in rhr_data and
len(rhr_data["activities-heart"]) > 0 and
"restingHeartRate" in rhr_data["activities-heart"][0]["value"]):
rhr_value = rhr_data["activities-heart"][0]["value"]["restingHeartRate"]
csv_file.write(f"{rhr_value}\n")
else:
csv_file.write("No RHR data\n")
def writeindex():
"""
CSV ヘッダーを書き込む(上書き初期化)。
"""
OUTPUT_FILE = USER_ID + "_RHR.csv"
with open(OUTPUT_FILE, 'w', encoding='utf-8') as csv_file:
csv_file.write("date,restingHeartRate\n")
# ------- 認証 ------- #
server = Oauth2.OAuth2Server(USER_ID, CLIENT_SECRET)
server.browser_authorize()
ACCESS_TOKEN = str(server.fitbit.client.session.token['access_token'])
REFRESH_TOKEN = str(server.fitbit.client.session.token['refresh_token'])
print(ACCESS_TOKEN)
print(REFRESH_TOKEN)
auth2_client = fitbit.Fitbit(
USER_ID,
CLIENT_SECRET,
oauth2=True,
access_token=ACCESS_TOKEN,
refresh_token=REFRESH_TOKEN
)
# ヘッダー初期化
writeindex()
# 取得対象期間(今日は固定日付,必要に応じて datetime.today() に変更)
today = date(2025, 10, 15)
for var in range(0, 7):
stamp = (today - timedelta(days=var)).strftime('%Y-%m-%d')
print(f"target: {stamp}", end=' ')
requestFitbit(stamp)
PythonでFitbit(2)
本ページの概要
Fitbitで測定した24時間心拍,24時間歩数,睡眠時間を,1週間分取得する方法を学習します。
PythonでFitbitデータを取得する
下記のプログラム「getWeekHR.py」をエディタで開発ディレクトリに作成し,USER_ID ,CLIENT_SECRET をセットします。さらにプログラム末尾の,
today=date(2025, 10, 15)
for var in range(0, 7):
部分をセットします。上記は「2025/10/15から遡って7日間のデータを取得する」という処理になります。
ターミナル上で,
python getWeekHR.py
と入力し,実行する。正常に動作すると,
「23QTVF_HR.csv」のようなファイルが開発ディレクトリに作成される。「getWeekSLEEP.py」,「getWeekSTEP.py」も同様に使用する。
#getWeekHR.py
import sys
import fitbit
import gather_keys_oauth2 as Oauth2
from datetime import datetime, date, timedelta
print('getWeekHR.py')
USER_ID = "hogehoge";
CLIENT_SECRET = "hogehoge"
def requestFitbit(DATE):
rval=""
global auth2_client,USER_ID
fitbit_stats = auth2_client.intraday_time_series('activities/heart', DATE, detail_level='1min')
HRstats = fitbit_stats['activities-heart-intraday']['dataset']
OUTPUT_FILE = USER_ID+"_HR.csv"
csv_file = open(OUTPUT_FILE, 'a')
csv_file.write(DATE+",")
for num1 in range(24):
for num2 in range(60):
key='{:02}'.format(num1)+':{:02}'.format(num2)+':00'
hr=""
for var in range(0, len(HRstats)):
if str(HRstats[var]['time']) == key:
hr=str(HRstats[var]['value'])
break
csv_file.write(hr)
csv_file.write(",")
csv_file.write("\n")
csv_file.close()
return rval
##################################################
def writeindex():
global USER_ID
OUTPUT_FILE = USER_ID+"_HR.csv"
csv_file = open(OUTPUT_FILE, 'a')
csv_file.write(",")
for num1 in range(24):
for num2 in range(60):
key='{:02}'.format(num1)+':{:02}'.format(num2)+':00'
csv_file.write(key)
csv_file.write(",")
csv_file.write("\n")
csv_file.close()
##################################################
"""Get tokens"""
server = Oauth2.OAuth2Server(USER_ID, CLIENT_SECRET)
server.browser_authorize()
ACCESS_TOKEN = str(server.fitbit.client.session.token['access_token'])
REFRESH_TOKEN = str(server.fitbit.client.session.token['refresh_token'])
"""Authorization"""
auth2_client = fitbit.Fitbit(USER_ID, CLIENT_SECRET, oauth2=True, access_token=ACCESS_TOKEN, refresh_token=REFRESH_TOKEN)
"""request"""
writeindex()
today=date(2025, 10, 15)
for var in range(0, 7):
stamp=datetime.strftime(today - timedelta(days=var), '%Y-%m-%d')
print("target: " + stamp)
requestFitbit(stamp)
#getWeekSTEP.py
import sys
import fitbit
import gather_keys_oauth2 as Oauth2
from datetime import datetime, date, timedelta
print('getWeekSTEP')
USER_ID = "hoge";
CLIENT_SECRET = "hoge"
def requestFitbitSteps(DATE):
global auth2_client, USER_ID
fitbit_stats = auth2_client.intraday_time_series('activities/steps', DATE, detail_level='1min')
STEPstats = fitbit_stats['activities-steps-intraday']['dataset']
OUTPUT_FILE = USER_ID + "_STEP.csv"
with open(OUTPUT_FILE, 'a') as csv_file:
csv_file.write(DATE + ",")
for hour in range(24):
for minute in range(60):
key = '{:02}:{:02}:00'.format(hour, minute)
steps = ""
for entry in STEPstats:
if entry['time'] == key:
steps = str(entry['value'])
break
csv_file.write(steps + ",")
csv_file.write("\n")
def writeStepIndex():
OUTPUT_FILE = USER_ID + "_STEP.csv"
with open(OUTPUT_FILE, 'a') as csv_file:
csv_file.write(",")
for hour in range(24):
for minute in range(60):
key = '{:02}:{:02}:00'.format(hour, minute)
csv_file.write(key + ",")
csv_file.write("\n")
# OAuth2 認証
server = Oauth2.OAuth2Server(USER_ID, CLIENT_SECRET)
server.browser_authorize()
ACCESS_TOKEN = str(server.fitbit.client.session.token['access_token'])
REFRESH_TOKEN = str(server.fitbit.client.session.token['refresh_token'])
auth2_client = fitbit.Fitbit(USER_ID, CLIENT_SECRET, oauth2=True,
access_token=ACCESS_TOKEN, refresh_token=REFRESH_TOKEN)
# 実行処理
writeStepIndex()
today = date(2025, 10, 15)
for i in range(7):
target_date = datetime.strftime(today - timedelta(days=i), '%Y-%m-%d')
print("target: " + target_date)
requestFitbitSteps(target_date)
#getWeekSLEEP.py
import sys
import fitbit
import pandas as pd
import gather_keys_oauth2 as Oauth2
from datetime import datetime, date, timedelta
print('getWeekSLEEP')
USER_ID = "hoge";
CLIENT_SECRET = "hoge"
def requestFitbit(DATE):
rval=""
global auth2_client,USER_ID
#fitbit_stats = auth2_client.intraday_time_series('activities/minutesSedentary', DATE, detail_level='1min')
#HRstats = fitbit_stats['activities-minutesSedentary-intraday']['dataset']
sleep_data = auth2_client.sleep(date=DATE)
#print(DATE+"睡眠データ取得実行しました")
#OUTPUT_FILE = "SLEEP.csv"
OUTPUT_FILE = USER_ID+"_SLEEP.csv"
csv_file = open(OUTPUT_FILE, 'a')
csv_file.write(DATE+",")
sleepcnt=len(sleep_data["sleep"])
#print(str(sleepcnt)+"回眠っています")
if sleepcnt>0:
totallength=0;
TAfter=0;
TFall=0;
TAwake=0;
TLessCnt=0;
TLessDur=0;
TEffi=0;
for var in range(0, sleepcnt):
#print("睡眠:"+str(var))
totallength+=sleep_data["sleep"][var]["minutesAsleep"] #総睡眠時間
TAfter+=sleep_data["sleep"][var]["minutesAfterWakeup"]
TFall+=sleep_data["sleep"][var]["minutesToFallAsleep"]
TAwake+=sleep_data["sleep"][var]["minutesAwake"]
TLessCnt+=sleep_data["sleep"][var]["restlessCount"]
TLessDur+=sleep_data["sleep"][var]["restlessDuration"]
TEffi+=sleep_data["sleep"][var]["efficiency"]
#AvgEffi=TEffi/sleepcnt;
AvgEffi=0;
print(str(sleepcnt)+"回の睡眠で総睡眠時間は"+str(totallength)+"分です")
csv_file.write(str(totallength)+","+str(sleepcnt)+","+str(TAfter)+","+str(TFall)+","+str(TAwake)+","+str(TLessCnt)+","+str(TLessDur)+","+str(AvgEffi)+",")
for var in range(0, sleepcnt):
if sleep_data["sleep"][var]["isMainSleep"] == True:
csv_file.write(sleep_data["sleep"][var]["startTime"]+","+str(sleep_data["sleep"][var]["minutesAsleep"])+","+str(sleep_data["sleep"][var]["efficiency"]))
else:
csv_file.write(",,,,,,,,,,,")
print("睡眠データがありません")
csv_file.write("\n")
csv_file.close()
return rval
##################################################
def writeindex():
global USER_ID
#OUTPUT_FILE = "SLEEP.csv"
OUTPUT_FILE = USER_ID+"_SLEEP.csv"
csv_file = open(OUTPUT_FILE, 'a')
csv_file.write("date,totallength,count,AfterWakeup,FallAsleep,Awake,restlessCount,restlessDur,AvgEffic,MainStart,MainLen,MainEffic\n")
csv_file.close()
##################################################
"""Get tokens"""
server = Oauth2.OAuth2Server(USER_ID, CLIENT_SECRET)
server.browser_authorize()
ACCESS_TOKEN = str(server.fitbit.client.session.token['access_token'])
REFRESH_TOKEN = str(server.fitbit.client.session.token['refresh_token'])
#print(ACCESS_TOKEN)
#print(REFRESH_TOKEN)
"""Authorization"""
auth2_client = fitbit.Fitbit(USER_ID, CLIENT_SECRET, oauth2=True, access_token=ACCESS_TOKEN, refresh_token=REFRESH_TOKEN)
"""request"""
#requestFitbit("2022-02-22")
writeindex(); #インデックス記入
#today = datetime.today()
today=date(2025, 10, 15)
for var in range(0, 7):
#day=today + timedelta(days=1)
#print(var+":" + datetime.strftime(yesterday, '%Y-%m-%d'))
stamp=datetime.strftime(today - timedelta(days=var), '%Y-%m-%d')
print("target: " + stamp, end=' ')
requestFitbit(stamp)
PythonでFitbit(1)
本ページの概要
PythonでFitbitデータを取得する基本的な方法を学習します。具体的には,(1)Python実行環境であるAnacondaのインストール,(2)Fitbitデータ取得用開発環境のダウンロード,(3)Fitbitデベロッパーサイトでのテストアプリケーションの作成,(4)サンプルコードの実行,を学びます。
Anacondaのインストール
Python実行環境である、Anacondaをインストールする。Anacondaをインストールしたら,EnvironmentからFITBITを作成し,ターミナルを開く。さらに,下記サイトから,開発環境を,自分のマシンの開発用ディレクトリ(C:\FITBIT)にコピーしてくる。
GitHub – orcasgit/python-fitbit: Fitbit API Python Client Implementation
AnacondaのTerminalで,下記コマンドを実行する。
pip install -r requirements/base.txt
pip install cherrypy
Fitbitアプリケーションの用意
FitbitDevelopperサイトの,「Manage>Register APP」からアプリケーション情報を入力する。URLは全て「http://kodamalab.sakura.ne.jp/wordpress/?p=46853」で良い。RedirectURLは「http://127.0.0.1:8080/」に設定する。登録後に表示される,「OAuth 2.0 Client ID」と「Client Secret」が必要になる。
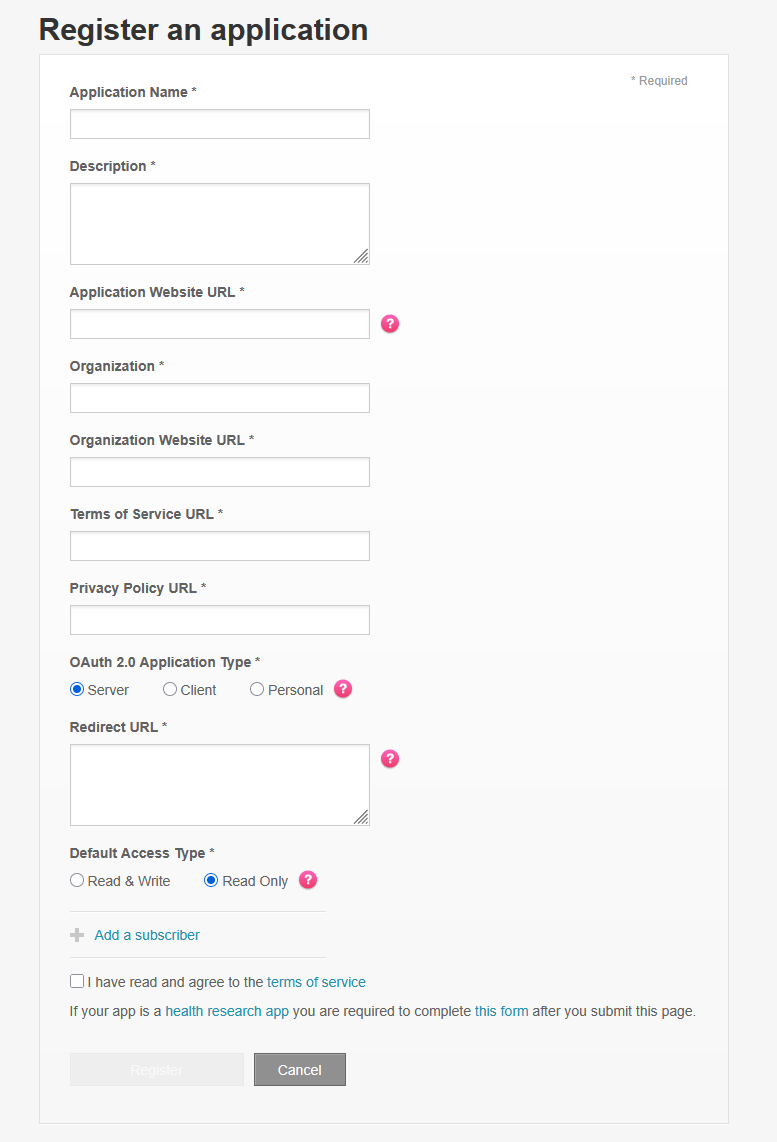
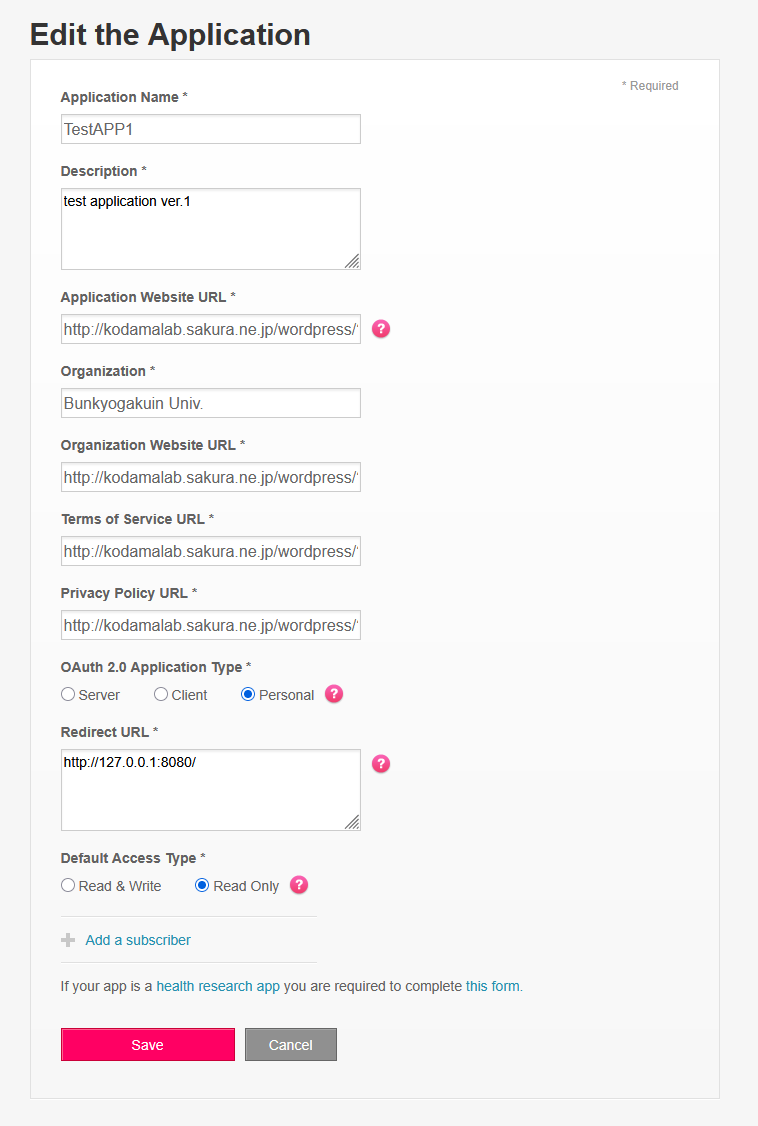
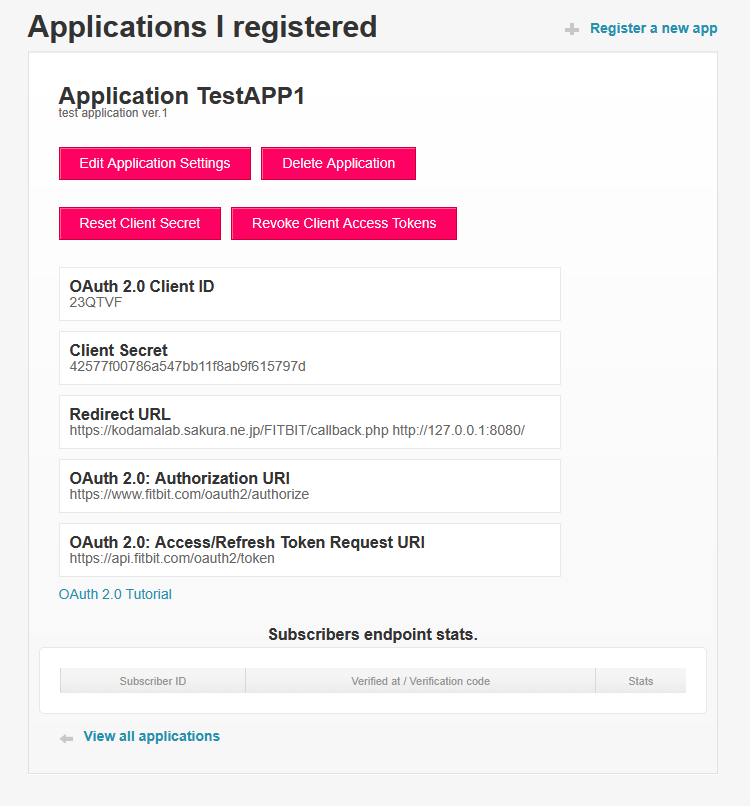
PythonでFitbitデータを取得する
下記のプログラム「fitbitTest.py」をエディタで開発ディレクトリに作成し,プログラムのUSER_ID ,CLIENT_SECRET ,DATEをセットします。ターミナル上で,
python fitbitTest.py
と入力し,実行する。正常に動作すると,
「STEP2025-10-15.csv」「HR_2025-10-15.csv」「CALO2025-10-15.csv」
などのファイルが開発ディレクトリに作成される。
#fitbitTest.py
import sys
import fitbit
import gather_keys_oauth2 as Oauth2
print('Hello FitbitAPP3')
USER_ID = "hogehoge"
CLIENT_SECRET = "hogehoge"
DATE = "2025-10-15" # 取得したい日付
server = Oauth2.OAuth2Server(USER_ID, CLIENT_SECRET)
server.browser_authorize()
ACCESS_TOKEN = str(server.fitbit.client.session.token['access_token'])
REFRESH_TOKEN = str(server.fitbit.client.session.token['refresh_token'])
#print(ACCESS_TOKEN) print('\n')
#print(REFRESH_TOKEN)print('\n')
"""Authorization"""
auth2_client = fitbit.Fitbit(USER_ID, CLIENT_SECRET, oauth2=True, access_token=ACCESS_TOKEN, refresh_token=REFRESH_TOKEN)
"""Getting data"""
#print('Getting data\n')
#fitbit_stats = auth2_client.intraday_time_series('activities/heart', DATE, detail_level='1min')
##################################################
fitbit_stats = auth2_client.intraday_time_series('activities/heart', DATE, detail_level='1min')
stats = fitbit_stats['activities-heart-intraday']['dataset']
OUTPUT_FILE = "HR_%s.csv" % DATE
csv_file = open(OUTPUT_FILE, 'w')
for var in range(0, len(stats)):
csv_file.write(stats[var]['time'])
csv_file.write(",")
csv_file.write(str(stats[var]['value']))
csv_file.write("\n")
csv_file.close()
##################################################
fitbit_stats = auth2_client.intraday_time_series('activities/steps', DATE, detail_level='1min')
stats = fitbit_stats['activities-steps-intraday']['dataset']
OUTPUT_FILE = "STEP%s.csv" % DATE
csv_file = open(OUTPUT_FILE, 'w')
for var in range(0, len(stats)):
csv_file.write(stats[var]['time'])
csv_file.write(",")
csv_file.write(str(stats[var]['value']))
csv_file.write("\n")
csv_file.close()
##################################################
fitbit_stats = auth2_client.intraday_time_series('activities/calories', DATE, detail_level='1min')
stats = fitbit_stats['activities-calories-intraday']['dataset']
OUTPUT_FILE = "CALO%s.csv" % DATE
csv_file = open(OUTPUT_FILE, 'w')
for var in range(0, len(stats)):
csv_file.write(stats[var]['time'])
csv_file.write(",")
csv_file.write(str(stats[var]['value']))
csv_file.write("\n")
csv_file.close()